WebAssembly, мониторинг и поисковые движки

Сегодня мы узнаем, что можно создать на базе WebAssembly и как построить пирамиду из оповещений мониторинга. Бонусом расскажем про топ-5 альтернатив Elasticsearch. Приятного чтения!
А нужны ли контейнеры
WebAssembly есть за что любить. По словам создателя Docker OSI, если бы WASM и его системный интерфейс WASI появились бы на свет в 2008 году, то необходимости в создании Docker просто не было бы. Идея построить распределённую систему на основе WASM нашла своё отражение в проекте Timecraft, который сейчас находится в активной разработке. Это гибрид из среды исполнения, оркестратора задач, «песочницы» и «машины времени».
Построить такую систему с нуля было бы слишком сложно. Так что в качестве языка программирования был выбран Go, а за основу взят WASM-рантайм для Go-разработчиков. Timecraft — платформа для запуска любых приложений, скомпилированных для WASM, но с рядом полезных возможностей.
По замыслу авторов внутри такой платформы будет возможность выполнять низкоуровневую запись взаимодействий, например, сетевых подключений на уровне сокетов. Такой трюк даст возможность отслеживания сообщений вне зависимости от используемого протокола.
Система будет спроектирована, чтобы записывать всё, что происходит во время исполнения гостевых приложений в некий примитив, «машину времени». Из полученных данных можно будет извлекать высокоуровневую телеметрию или даже выполнять функциональное моделирование.
Трудность в том, что при подобной записи генерируется огромное количество данных. Они занимают много места даже при включённых механизмах сжатия и их трудно использовать. Авторы проекта считают, что им удастся преодолеть эти сложности и научиться эффективно использовать сохранённые данные. Ну а пока добавим их репозиторий в избранное, поставим звёздочку и пожелаем успеха!
Пирамида оповещений
Даже хорошо спроектированные системы сбоят. Одного неверно сформированного или повреждённого сообщения иногда достаточно, чтобы вызвать проблемы в заботливо сформированном пайплайне. В таких случаях специалисты пристально изучают сбой и находят его первоисточник. Потом делается заплатка, позволяющая коду работать бесперебойно в этой конкретной ситуации.
Такой подход у некоторых вызывает недоумение: почему программисты не позаботились о возникновении такой ситуации на начальном этапе? Это бы сэкономило немало времени, которое сейчас пришлось потратить на поиск возникшей проблемы. На такой вопрос можно дать несколько ответов.
Первый, он же основной — бизнес не хочет ждать. Чем быстрее будет внедрена новая фича, тем быстрее маркетинг сможет проверить свои гипотезы и потенциально принести прибыль. Ну а решать возникающие сложности можно по мере их поступления. Второй аргумент — хаотичность данных. К сожалению, почти невозможно предсказать все возможные сценарии использования данных. Так или иначе придётся искать баланс между эффективностью и надёжностью. Закономерно возникают пограничные случаи и отказы, которые приходится обрабатывать.
Один из инструментов, способных улучшить ситуацию — мониторинг. Его ценность даже не в том, чтобы зафиксировать произошедший сбой. Грамотный мониторинг может помочь выдать предупреждения о грядущей проблеме до того, как она произойдёт. Если сбой всё-таки случился, то получится быстро восстановить штатную работу. Например, в компании OTA Insight весь мониторинг разделили на несколько уровней, образующих общую иерархию предупреждений. Каждый раз, когда команда хочет внедрить новое решение, его можно заранее сопоставить с этой схемой:
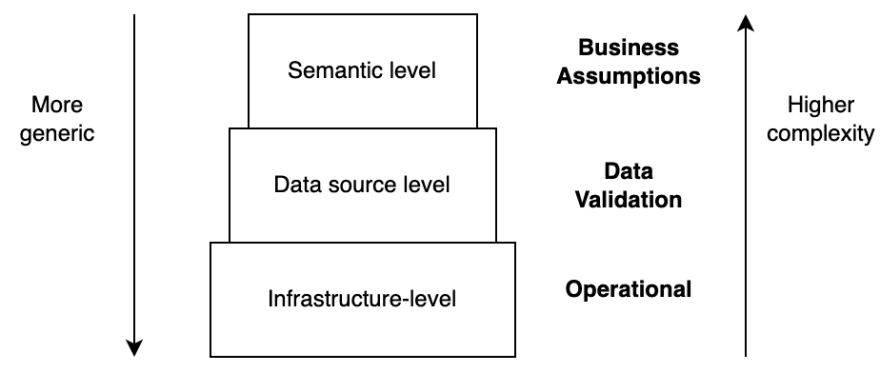
С лёгкой руки её можно назвать пирамидой предупреждений, на нижнем уровне которой лежит уровень инфраструктуры, а верхушкой является уровень семантики данных. Каждый из типов оповещений имеет свою собственную, внутреннюю иерархию, например, по важности. Оповещения с высокой важностью должны быть обработаны в первую очередь, а оповещения с низкой важностью должны быть изучены, но при этом не обязательно прямо сейчас. Стоит помнить, что любое оповещение низкой важности может сменить статус и начать наносить ущерб.
Тип Operational самый простой и служит общим индикатором исправности процессов. Сюда, например, можно отнести сбои железа. Второй тип, Data Validation, чуть сложнее, поскольку при его реализации надо иметь некий набор предварительных знаний. Например, можно посмотреть объём данных за предыдущие дни и сравнить его с текущим показателем. Если есть значительное отклонение, то о нём стоит сообщить. Третий же тип оповещений, Business Assumptions, должен принадлежать исключительно команде, которая владеет данными и хорошо понимает контекст.
Помимо того, что иерархия предупреждений помогает выявлять причину каждого возникающего сбоя, она даёт несколько полезных бонусов. Становится легче разделить обязанности по командам и есть представление, какими знаниями надо обладать для решения проблемы. В результате управлять ошибками станет проще, равно как и выделять целевые средства на повышение надёжности.
Альтернативы Elasticsearch
На первый взгляд может показаться, что у Elasticsearch не так много прямых аналогов. Хотите обычный инструмент с открытым исходным кодом — OpenSearch. Готовы потратить ресурсы на доработку — Solr. Ну а для сложных сценариев можно рассмотреть и ClickHouse. Но на деле альтернатив значительно больше, вот некоторые из них:
Algolia — облачный сервис, объединяющий в себе быстрый поисковый движок и фичи AI. Они расширяют возможности поиска похожих вопросов или иных формулировок. Algolia отлично подойдёт, чтобы прикрутить автодополнение или поиск по геолокации с фильтрацией и ранжированием. Его легко интегрировать в приложения, построенные на React, Vue, Angular, Android или Flutter.
MeiliSearch — API для поиска, вдохновлённый Algolia, но имеющий открытый исходный код. Хорошо подходит в качестве поискового движка для завершения в небольших наборах данных. Его можно хостить самостоятельно или в любом публичном облаке.
Vespa — это не только прекрасный итальянский бренд мототехники, но и поисковая платформа, созданная Yahoo. А ещё это и база данных векторов, которые, по мнению некоторых разработчиков, являются новым JSON. Идеально для обработки крупных датасетов.
Xapian — библиотека с открытым исходным кодом, позволяющая решить классическую задачу полнотекстового индексирования и поиска на основе функции ранжирования Okapi BM25. Несмотря на богатый синтаксис запросов, у Xapian пока отсутствуют некоторые современные функции, в частности, векторный тип данных.
Bleve — ещё одна библиотека, используемая в Go для классической индексации на основе структур языка. Позволяет выполнять сложный поиск, но не подходит для распределённых Go-приложений.
Конечно, такие небольшие платформы и сервисы не могут полноценно тягаться с гигантами, вроде Elasticsearch. Но порой этого и не требуется. Так что если перед вами стоит простая задача, то имеет смысл найти простое же решение. Если вам хочется больше альтернатив, то в этой статье вы найдёте ещё 6 отличных поисковых движков.
Митапы
DevOps Meetup
25 октября 2023
Осенью у нас запланирован DevOps Meetup. Программа мероприятия формируется, но регистрация уже открыта. Кстати, вы уже можете подать доклад прямо в режиме онлайн. Заявки на участие спикера принимаются до 5 октября.
Интересуетесь нашими мероприятиями? В Telegram-канале Evrone meetups мы выкладываем анонсы с подробными описаниями докладов, а также студийные записи прошедших митапов. Тем для кого выступать в новинку, мы оказываем всяческую поддержку и помогаем оформить экспертизу в яркое выступление. Подписывайтесь и пишите @andrew_aquariuss, чтобы узнать подробности.
Вакансии
Evrone
Мы открыты для новых DevOps-инженеров. В Evrone можно работать удалённо с первого дня, мы поддерживаем и оплачиваем участие в Open-source проектах, а расти в грейдах можно с помощью честной системы проверки навыков и менторства.